



03. dubna '19




Idea architektury systému založeném na mikroservisách (mikroslužbách) není nikterak nová (najdeme ji už v návrhu operačního systému Unix a v obecném slova smyslu je na ní postavena architektura celého internetu). V posledních letech se však masivně vrátila jako návrhový vzor pro moderní distribuované systémy (první implementace v podobě případových studií se objevily v roce 2012) a za tento krátký čas si stačila najít mnoho příznivců, ale také odpůrců.
Navrhnout takový systém znamená rozložit jeho funkcionalitu na malé, samostatně běžící komponenty (mikroservisy), které spolu při správném návrhu obvykle přímo nekomunikují (klade se důraz na jejich maximální nezávislost), nýbrž poskytují své služby gatewayi (vyšší servisní vrstvě). Ta většinou vytváří centrální bod architektury a jednotné rozhraní mezi klientem a distribuovaným systémem – přijímá požadavky od klienta, přeposílá je do příslušných mikroservis a také naopak skládá jejich odpovědi a posílá zpět klientovi. Dodnes ovšem neexistuje žádná přesná specifikace, jak mikroservisy navrhovat a implementovat. Opakem mikroservis jsou monolytické aplikace.
Dekompozice systému na menší celky umožňuje jeho lepší pochopení, snadnější vývoj a testování; pro vývoj jedné mikroservisy není třeba velký tým. Lze je také nasazovat nezávisle na sobě a jednoduše tak i updatovat a tím prodlužovat „trvanlivost“ systému. Díky jednotnému komunikačnímu protokolu může být každá komponenta napsána v jiném programovacím jazyce a užívat jednak různá databázová schémata, ale také různá softwarová či hardwarová prostředí. Nespornou výhodou tohoto přístupu je škálovatelnost – jednotlivé mikroservisy lze jednoduchým vícenásobným nasazením paralelizovat a rozložit tak lépe zátěž na serverech. Navíc tím zvyšujeme odolnost vůči případným chybám, tzv. fault tolerance (pokud mikroservisa přestane fungovat, ostatní tímto výpadkem nejsou vůbec zasaženy). Celý systém se tak chová dynamicky a lépe reaguje na změny provozních podmínek.
Už z principu není vždy snadné systém správně dekomponovat na jednotlivé uzavřené celky, návrhu tak vždy předchází jeho důkladná analýza. Zde musíme navíc zohlednit fakt, že komunikace mezi jednotlivými mikroservisami prostřednictvím HTTP requestů je vždy mnohem pomalejší než v rámci jednoho procesu, proto se ji snažíme omezovat na minimum. Obtížná je také údržba rozhraní mikroservis. Jelikož obě strany musí vždy rozumět přenášeným zprávám, nevyhnutelně zde dochází k duplicitám kódu. Navíc, pokud dojde k nějaké změně tohoto rozhraní, musíme v nejhorším případě upravit všechny komponenty systému, pokud jsou na něm závislé. K jednomu z nejpalčivějších problémů patří distribuované transakce, tj. atomické operace nad databází, které je potřeba udělat nad voláním několika mikroservis. To může činit značné problémy, zvláště, když každá mikroservisa používá vlastní databázi. Řešením je opět navrhnout dekompozici tak, abychom se distribuovaným transakcím pokud možno vyhnuli.
Čím komplexnější software nad popisovanou architekturou stavíte, tím více v něm bude přibývat také mikroservis a tím bude také stále složitější se v něm vyznat. Nadto průběžně sledovat jeho výkonnost a odhalovat jeho slabá místa je prakticky nemožné. Přesto však v případě chyby mikroservisy musíme tuto událost snadno odhalit a službu restartovat či opravit nebo pokud nastanou výkonnostní problémy na některé z nich, zahájit její škálování. Z toho vyplývá nutnost automatického monitoringu (sledování v reálném čase) všech mikroservis, které se podílejí na stavbě celého systému. Aby vše probíhalo hladce a běh systému nebyl příliš ovlivněn, klademe na použitý monitorovací nástroj několik požadavků:
Myšlenka sledování stavu mikroservis je založena na odchytávání každého HTTP požadavku a odpovědi na něj a následné vyhodnocování.
Na rozdíl od monolitického systému ve světě mikroservis pracujeme s mnohem větším počtem přístupových bodů, tím pádem se zvyšuje i možnost selhání. Navíc v případě, že na chybující mikroservise jsou závislé další, tato chyba se pak řetězově šíří dál. Je tudíž výhodné v systému použít nástroje, které jednak umožňují jeho monitoring, ale také ty, co sami zvyšují odolnost vůči chybám.
Hystrix je jeden z kategorie výše popisovaných nástrojů od Netflixu. Jedná se o knihovnu primárně určenou pro zabránění řetězení chyb v systému, pokud nastanou, čímž se rapidně sníží čas odezvy a také zátěž pro celý systém (zabrání se následnému dalšímu volání jiných mikroservis) a pro real-time monitoring. Další skvělou vlastností je dynamická změna vlastní konfigurace za běhu.
Instalace je velmi jednoduchá – i s uživatelským rozhraní na dashboardu je knihovna k dispozici na stránkách projektu zde.
Stačí stažený .war soubor nakopírovat do Tomcatu a nechat naběhnout. Hystrix sbírá metriky z implementací HystrixCommand rozhraní, a to vždy při provolání jeho metody run(). Optimální je tedy obalit všechna volání jiných mikroservis tímto rozhraním – vždy když se bude volat jakákoliv mikroservisa, do statistik se přenesou aktuální metriky:
public class HelloWorldCommand extends HystrixCommand<String> {private final String name;
public CommandHelloWorld(String name) {
super(HystrixCommandGroupKey.Factory.asKey("Nazev skupiny"));
this.name = name;
}@Override
protected String run() {
// Provolani HystrixCommand a mikroservisy PERSON
return callMicroservice(PERSON);
}@Override
protected HttpResponse getFallback() {
// Reakce na chybovy stav
}
}Důležitý je parametr HystrixCommandGroupKey – podle něj se budou na dashboardu data agregovat do skupin.
V případě, že se volání nestačí v určitém čase provést (výchozí je 1 sekunda), Hystrix dále nečeká na propagaci případných chyb a označí ho jako „fault“. Místo metody run() se v tomto případě zavolá metoda getFallback(), kde si můžeme sami implementovat, jak na takovou situaci reagovat.)
Kromě nastavení sbírání metrik je třeba ještě správně nastavit dashboard. Všechna data, která zobrazuje, přichází ve streamu (hystrix.stream), který je nutné nejprve zaregistrovat v nastavení web.xml v mikroservise, ze které sbíráme data:
<servlet-mapping> <servlet-name>HystrixMetricsStreamServlet</servlet-name> <url-pattern>/hystrix.stream</url-pattern> </servlet-mapping>
Vlastní dashboard nalezneme na adrese http://<jméno a port hystrix serveru>/hystrix . Na první obrazovce je třeba vyplnit URL discovery serveru a hystrix streamu, viz níže, následně kliknout na tlačítko Add Stream a potvrdit Monitor Streams.
Objeví se monitorovací dashboard, viz níže, kde v jeho horní polovině uvidíme všechny definované HystrixCommands a v dolní polovině data podle názvu HystrixCommandGroupKey, která jsou zde zároveň názvy mikroservis. Pro zobrazení statistik je nutné HystrixCommand nejprve provolat.
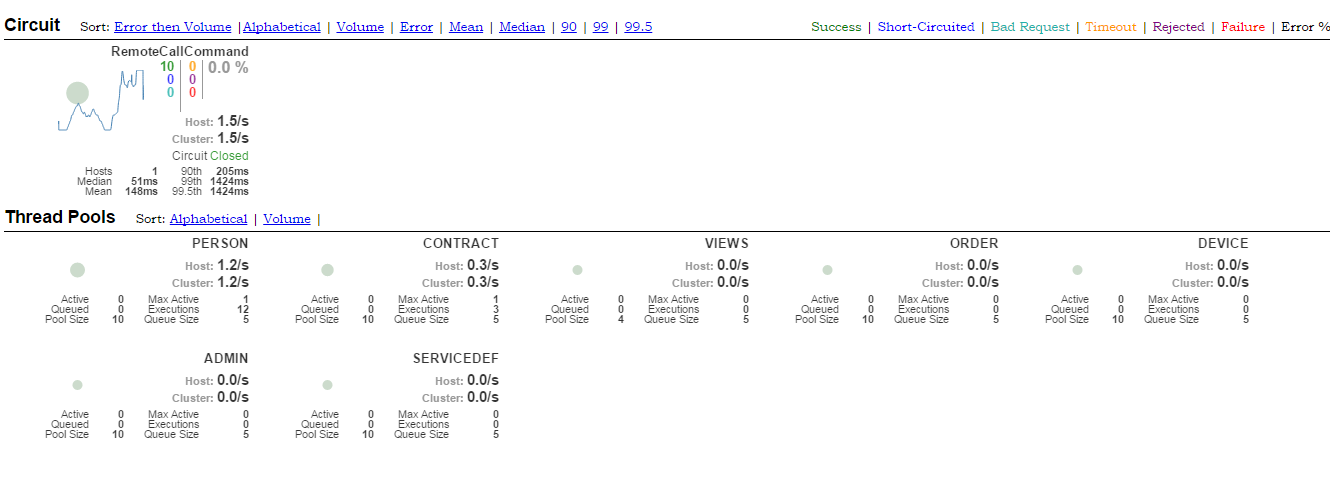
V případě, že mikroservisa bude nějaký čas nedostupná, po určitém počtu opakování (výchozí je 20, ale lze překonfigurovat) se HystrixCommand otevře a výkonný kód v run() se nezavolá – tím v případě chyby nedochází k zátěži serveru. V monitoringu na dashboardu uvidíme u příslušného HystrixCommandu místo Circuit: Closed Circuit:Opened. Po uplynutí určité doby (výchozí je 5 sekund) se vždy 1 voláním vyzkouší, zda už mikroservisa odpovídá. Pokud ano, okruh se uzavře a volání opět probíhá v pořádku.
V oblasti monitoringu mikroservis existuje mnohem víc zajímavých nástrojů, namátkou např. AppDynamics, Instana nebo Netsil, které jsou po grafické stránce velmi povedené, bohužel se však jedná o placený software. V oblasti open source zatím stále příliš mnoho nástrojů nenajdeme, kromě zmíněného Hystrixu se používá také Prometheus, původně navržený pro monitoring na SoundCloudu.
Zpět


